Parallelized Barnes-Hut
A parallelized Barnes-Hut algorithm designed to run natively on a GPU using the CUDA framework. By shifting the workload away from the CPU, this implementation achieved over a 12x efficiency increase compared to traditional CPU-bound algorithms.
The core of this project heavily focused on fine-tuned concurrency control and strict GPU memory management, actively balancing between shared, local, and global memory to prevent bottlenecks.
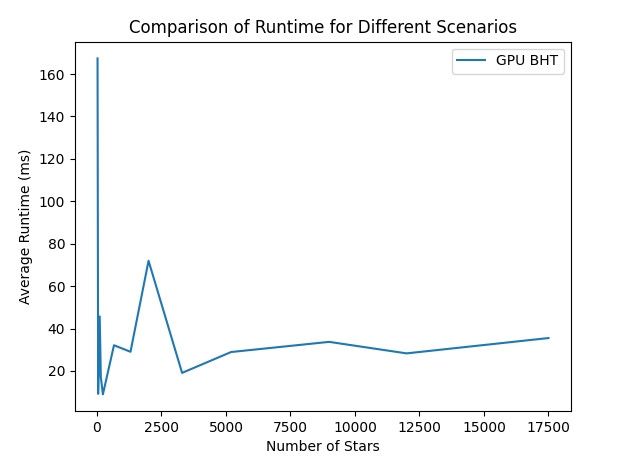
The Four-Kernel Pipeline
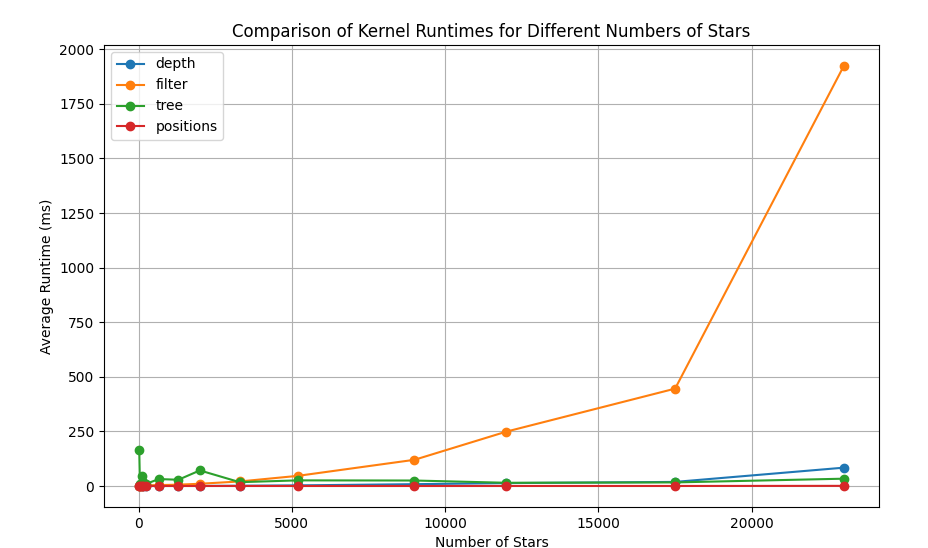
To maximize throughput, the engine dispatches four distinct kernels per frame, capable of generating 30 frames of 12,000 bodies in under a minute. The general execution pipeline is:
- Kernel 1: Filter out and combine overlapping stars to clamp the maximum tree depth.
- Kernel 2: Traverse and find the maximum depth of the newly filtered tree.
- CPU Step: Allocate a linear array in memory for the found tree depth.
- Kernel 3: Populate the allocated Barnes-Hut Tree (BHT) with each node.
- Kernel 4: Compute the updated positions and velocities of the stars.
Encountered Issues
I hit a slight snag during development: without a local CUDA-enabled GPU, I had to compile and run everything through Google Colab. This created a massive roadblock for real-time visualization.
To verify the physics and visualize the data, I introduced an additional CPU-bound step at the end of each frame that serialized and saved the positional data, allowing me to render the final results offline.